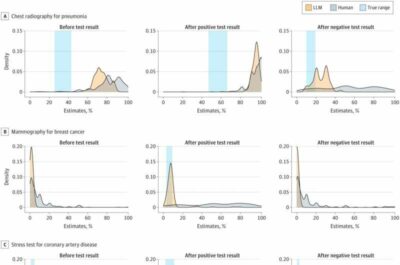
Chatbot AI-Immagine:grafici di densità delle distribuzioni delle risposte. LLM indica un modello linguistico di grandi dimensioni. Credito: JAMA Network Open (2023).
I medici-ricercatori del Beth Israel Deaconess Medical Center (BIDMC) hanno confrontato il ragionamento probabilistico di un chatbot con quello dei medici umani. I risultati, pubblicati su JAMA Network Open, suggeriscono che l’intelligenza artificiale potrebbe fungere da utile strumento di supporto alle decisioni cliniche per i medici.
“Gli esseri umani lottano con il ragionamento probabilistico, la pratica di prendere decisioni basate sul calcolo delle probabilità”, ha affermato l’autore corrispondente dello studio, Adam Rodman, MD, medico di medicina interna e ricercatore presso il Dipartimento di Medicina del BIDMC. “Il ragionamento probabilistico è uno dei tanti componenti della formulazione di una diagnosi, che è un processo incredibilmente complesso che utilizza una varietà di diverse strategie cognitive. Abbiamo scelto di valutare il ragionamento probabilistico isolatamente perché è un’area ben nota in cui gli esseri umani potrebbero avere bisogno di supporto“.
Basando il loro studio su un sondaggio nazionale precedentemente pubblicato su più di 550 professionisti che eseguivano ragionamenti probabilistici su cinque casi medici, Rodman e colleghi hanno alimentato il Large Language Model (LLM), Chat GPT-4, disponibile al pubblico, con la stessa serie di casi.
Il chatbot, proprio come i professionisti prima di loro, aveva il compito di stimare la probabilità di una determinata diagnosi in base alla presentazione dei pazienti. Quindi, dati i risultati di test come la radiografia del torace per la polmonite, la mammografia per il cancro al seno, lo stress test per la malattia coronarica e un’urinocoltura per l’infezione del tratto urinario, il programma chatbot ha aggiornato le sue stime.
Quando i risultati dei test erano positivi, c’era una sorta di pareggio; il chatbot è stato più accurato nel fare diagnosi rispetto agli umani in due casi, altrettanto accurato in due casi e meno accurato in un caso. Ma quando i test sono risultati negativi, il chatbot ha brillato, dimostrando in tutti e cinque i casi una maggiore precisione nel fare diagnosi rispetto agli esseri umani.
“Gli esseri umani a volte ritengono che il rischio sia maggiore in un test risultato positivo rispetto a un risultato negativo del test, perchè il test positivo può portare a trattamenti eccessivi, a più test e a troppi farmaci“, ha affermato Rodman.
Ma Rodman è meno interessato a come i chatbot e gli esseri umani si comportano in sintonia, piuttosto a come le prestazioni dei medici altamente qualificati potrebbero cambiare in risposta alla disponibilità di queste nuove tecnologie di supporto nella clinica. Lui e i suoi colleghi stanno esaminando la cosa.
“Il Large Language Model non può accedere al mondo esterno: non calcola le probabilità nel modo in cui lo fanno gli epidemiologi o anche i giocatori di poker. Ciò che fa ha molto più in comune con il modo in cui gli esseri umani prendono decisioni probabilistiche immediate“, ha affermato Rodman.
Leggi anche:ChatGPT suggerisce probabili diagnosi al pronto soccorso
“Ma questo è ciò che è entusiasmante. Anche se imperfetta, la sua facilità d’uso e la capacità di essere integrata nei flussi di lavoro clinici potrebbero teoricamente far sì che gli esseri umani prendano decisioni migliori“, ha aggiunto il ricercatore. “La ricerca futura sull’intelligenza umana e artificiale collettiva è assolutamente necessaria“.
Fonte:JAMA Network Open