(SARS-CoV-2/ Immagine Credit Public Domain).
Un team di ricercatori esperti dell’HIV, biologi cellulari e biofisici che si sono uniti per supportare la ricerca su COVID-19, ha determinato la struttura atomica di una proteina del coronavirus chiamata ORF8 pensata per aiutare il patogeno a eludere e smorzare la risposta delle cellule immunitarie umane.
La mappa strutturale che è stata pubblicata sulla rivista PNAS ha gettato le basi per nuovi trattamenti antivirali su misura per SARS-CoV-2 e ha consentito ulteriori indagini su come il il virus appena emerso devasta il corpo umano.
“Utilizzando la cristallografia a raggi X, abbiamo costruito un modello atomico di ORF8 che ha evidenziato due regioni uniche: una che è presente solo in SARS-CoV-2 e il suo immediato antenato pipistrello e una che è assente da qualsiasi altro coronavirus”, ha detto l’autore principale James Hurley, un Professore della UC Berkeley ed ex scienziato del Lawrence Berkeley National Laboratory (Berkeley Lab).
“Queste regioni stabilizzano la proteina – che è una proteina secreta, non legata alle proteine spike caratteristiche del virus- e creano nuove interfacce intermolecolari. Noi, e altri nella comunità di ricerca, crediamo che queste interfacce siano coinvolte in reazioni che in qualche modo rendono SARS-CoV-2 più patogeno dei ceppi da cui si è evoluto “.
Biologia strutturale sotto i riflettori
La generazione di mappe della struttura proteica è sempre laboriosa, poiché gli scienziati devono progettare batteri in grado di pompare grandi quantità della molecola, manipolare le molecole in una forma cristallina pura e quindi acquisire molte, molte immagini di diffrazione dei raggi X dei cristalli. Queste immagini, prodotte come fasci di raggi X che rimbalzano sugli atomi nei cristalli e passano attraverso gli spazi vuoti nel reticolo, generando uno schema di punti, vengono combinate e analizzate tramite uno speciale software per determinare la posizione di ogni singolo atomo. Questo meticoloso processo può richiedere anni, a seconda della complessità della proteina.
Per molte proteine, il processo di costruzione di una mappa viene aiutato confrontando la struttura della molecola irrisolta con altre proteine con sequenze di amminoacidi simili che sono già state mappate, consentendo agli scienziati di fare ipotesi informate su come la proteina si ripiega nella sua forma 3D.
Ma per ORF8, il team ha dovuto ricominciare da capo. La sequenza di amminoacidi di ORF8 è così diversa da qualsiasi altra proteina che gli scienziati non avevano alcun riferimento per la sua forma complessiva, ed è la forma 3D di una proteina che determina la sua funzione.
Hurley e i suoi colleghi della UC Berkeley, esperti nell’analisi strutturale delle proteine dell’HIV, hanno lavorato con Marc Allaire, un biofisico ed esperto di cristallografia presso il Berkeley Center for Structural Biology, situato presso l’Advanced Light Source (ALS) del Berkeley Lab. Insieme, il team ha lavorato in overdrive per sei mesi: il laboratorio di Hurley ha generato campioni di cristalli e li ha passati ad Allaire, che avrebbe usato le linee di raggi X dell’ALS per acquisire le immagini di diffrazione. Ci sono volute centinaia di cristalli con più versioni della proteina e migliaia di immagini di diffrazione analizzate da speciali algoritmi informatici per mettere insieme la struttura di ORF8.
Vedi anche:SARS-CoV-2: come è saltato dal pipistrello all’uomo
“I coronavirus mutano in modo diverso rispetto a virus come l’influenza o HIV, che accumulano rapidamente molti piccoli cambiamenti attraverso un processo chiamato ipermutazione. Nei coronavirus, grossi pezzi di acidi nucleici a volte si muovono attraverso la ricombinazione “, ha spiegato Hurley. Quando ciò accade, possono apparire grandi e nuove regioni di proteine. Le analisi genetiche condotte molto presto nella pandemia di SARS-CoV-2 hanno rivelato che questo nuovo ceppo si era evoluto da un coronavirus che infetta i pipistrelli e che si era verificata una significativa mutazione di ricombinazione nell’area del genoma che codifica per una proteina, chiamata ORF7, trovato in molti coronavirus. La nuova forma di ORF7, denominata ORF8, ha rapidamente guadagnato l’attenzione di virologi ed epidemiologi perché eventi di divergenza genetica significativa come quello osservato per ORF8 sono spesso la causa della virulenza di un nuovo ceppo.
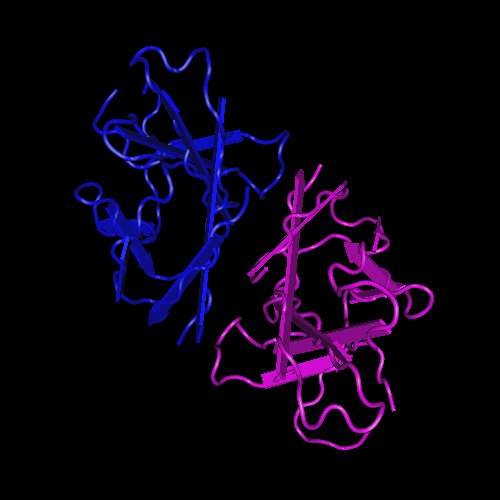
“C’è un nucleo di circa la metà che è correlato a un tipo di piega noto in una struttura risolta dai precedenti coronavirus, ma l’altra metà era completamente nuova”.

Un diagramma a nastro della struttura ORF8. Questa proteina è composta da due unità con sequenza e forma amminoacidiche identiche, legate insieme da un legame zolfo-zolfo. Credito immagine: Hurley Lab
SARS-CoV-2: i ricercatori si coalizzano
Come tanti scienziati che lavorano alla ricerca COVID-19, Hurley e i suoi colleghi hanno scelto di condividere le loro scoperte prima che i dati potessero essere pubblicati in una rivista peer-reviewed, consentendo ad altri di iniziare studi di follow-up di impatto mesi prima rispetto al processo di pubblicazione tradizionale. Come ha spiegato Allaire, la crisi di tutti i giorni causata dalla pandemia ha spostato tutti nella comunità di ricerca in una mentalità pragmatica. Piuttosto che preoccuparsi di chi ha realizzato qualcosa per primo, o di restare ai confini delle loro specifiche aree di studio, gli scienziati hanno condiviso presto i dati e spesso e hanno intrapreso nuovi progetti quando avevano le risorse e le competenze necessarie.
Il team sapeva dalla revisione dell’analisi genomica SARS-CoV-2 pubblicata a gennaio che ORF8 era un pezzo importante del puzzle della pandemia (allora molto più nebulosa), quindi i ricercatori si sono messi al lavoro.
Da allora gli autori sono passati ad altri progetti, soddisfatti di aver posto le basi per altri gruppi per studiare ORF8 in modo più dettagliato. (Attualmente, sono in corso diverse indagini incentrate su come ORF8 interagisce con i recettori cellulari e su come interagisce con gli anticorpi, poiché gli individui infetti sembrano produrre anticorpi che si legano a ORF8 oltre ad anticorpi specifici per le proteine di superficie del virus.)
Dalla sequenza alla struttura

Un rendering del diagramma a nastro della struttura ORF8 prevista da AlphaFold 2 (blu), sovrapposta alla struttura effettiva (verde) determinata dal team guidato dall’UC Berkeley. Credito immagine: DeepMind
Il sequenziamento di un gene o di una stringa di amminoacidi per comprendere i componenti di una proteina è facile e veloce per gli scienziati, ma studiare come una sequenza di amminoacidi interagisce per piegarsi nella forma fisica effettiva della proteina usando la cristallografia a raggi X o la criografia è complesso e richiede molto tempo. Di conseguenza, c’è stato un appello di lunga data all’interno della biologia per sviluppare strumenti in grado di prevedere con precisione la struttura di una proteina in base alla sua sequenza.
Negli ultimi decenni, l’apprendimento automatico è emerso come il leader in questa sfida. Questi programmi di intelligenza artificiale sono alimentati da grandi set di dati di strutture proteiche note in modo che imparino a identificare le correlazioni tra sequenza e forma di piegatura, trovando rapidamente modelli che impiegherebbero anni per essere scoperti dagli esseri umani. Una volta che il programma – chiamato algoritmo – è “addestrato” in questo modo, può essere utilizzato per costruire modelli predittivi di strutture proteiche irrisolte. E ogni volta che viene alimentato con una nuova struttura confermata, migliora.
Per testare quali sono gli algoritmi migliori, le aziende e le istituzioni organizzano concorsi, il più famoso dei quali è l’esperimento semestrale di valutazione critica della struttura delle proteine (CASP). L’anno scorso, ORF8 è stata selezionata come sfida finale della competizione CASP perché “si è distinta come eccezionalmente difficile da prevedere”, secondo Hurley. I migliori algoritmi sono stati liberati sulla struttura ORF8, così come su altre strutture. I giudici CASP sono stati in grado di selezionare un vincitore: AlphaFold 2, un algoritmo sviluppato da Google, derivato da DeepMind, che ha costruito strutture che si avvicinavano maggiormente agli obiettivi sperimentali, incluso quella di ORF8.
Fonte: UC Berkeley